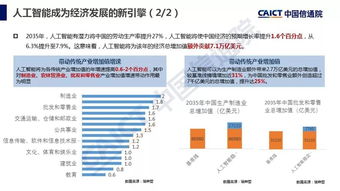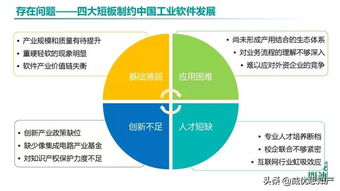
隨著人工智能技術的快速發展,大規模數據處理與高性能計算已成為智能應用落地的關鍵支撐。在人工智能基礎軟件開發中,有效整合大數據處理與高性能計算能夠顯著提升模型訓練效率和系統響應能力。以下是四個關鍵實現步驟,及其在人工智能基礎軟件開發中的具體應用。
第一步:高效數據采集與預處理
在人工智能開發中,高質量的數據是模型準確性的基礎。通過分布式數據采集工具(如Apache Kafka或Flink)實時收集多源異構數據,包括圖像、文本和傳感器數據。然后,利用高性能計算集群對數據進行并行清洗、去噪和特征提取,例如使用Apache Spark進行內存計算加速。這一步驟不僅減少了數據冗余,還通過預處理流水線為后續模型訓練提供標準化的輸入,顯著縮短了人工智能模型的數據準備時間。
第二步:分布式存儲與資源管理
為應對海量數據存儲需求,采用分布式文件系統(如HDFS)或對象存儲(如Amazon S3),確保數據高可用性和可擴展性。利用資源管理框架(如Kubernetes或YARN)動態分配計算資源,支持多任務并發執行。在人工智能開發中,這允許團隊同時運行多個模型訓練任務,并優化GPU/CPU利用率,從而提高開發迭代速度。例如,在深度學習場景中,通過容器化部署模型訓練環境,實現資源隔離和彈性伸縮。
第三步:并行算法設計與計算優化
針對人工智能算法的高計算復雜度,設計并行計算模型是關鍵。使用MPI(消息傳遞接口)或CUDA等框架,將機器學習任務(如神經網絡訓練)分解為子任務,并在多節點或GPU上并行執行。例如,在開發自然語言處理模型時,通過數據并行或模型并行策略加速Transformer架構的訓練過程。結合編譯器優化(如TVM)和硬件加速(如FPGA),進一步提升計算性能,降低人工智能基礎軟件的延遲。
第四步:智能調度與結果集成
通過智能調度系統(如Apache Airflow)協調數據處理與計算流程,確保任務依賴性和優先級管理。在人工智能應用中,這包括自動化模型訓練、評估和部署流水線。計算結果通過API或分布式數據庫(如Redis)集成到最終應用中,支持實時推理和反饋循環。例如,在開發推薦系統時,高性能計算處理用戶行為數據后,模型結果被快速推送到線上服務,實現低延遲個性化推薦。
這四個步驟形成了一個閉環流程:從數據準備到智能調度,不僅提升了大數據處理的效率,還直接賦能人工智能基礎軟件的開發,使其能夠應對復雜場景下的高性能需求。隨著硬件和算法的進步,這一流程將進一步優化,推動人工智能技術的廣泛應用。